
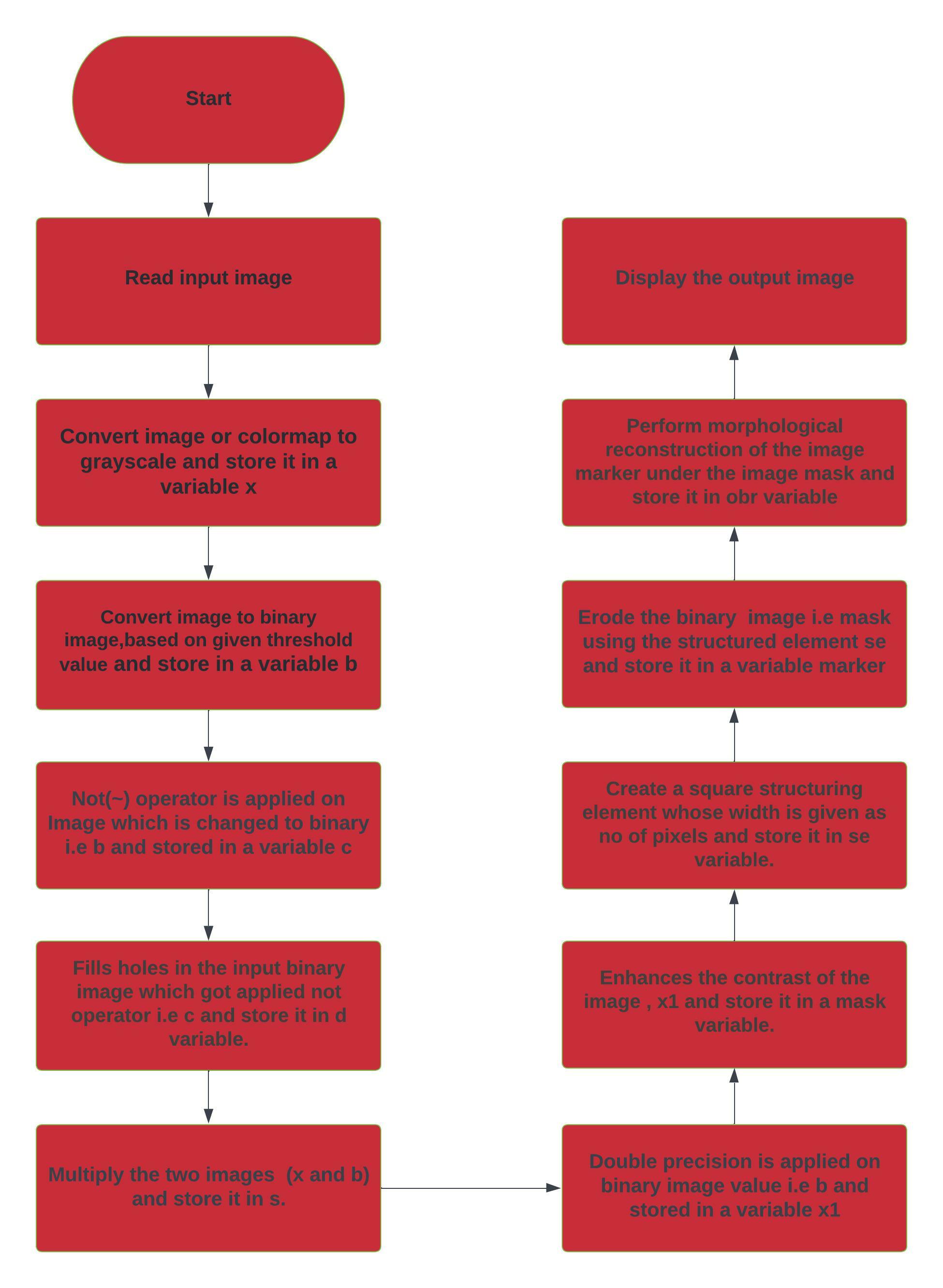
Flow chart for clustering
Cluster investigation or Clustering is the assignment of collection and arrangement of articles in such a path, to the point that questions in the same gathering (called a group) are more comparative (in some sense or another) to one another than to those in different gatherings (bunches). It is a primary assignment of exploratory information mining, and a typical method for measurable information examination, utilized as a part of numerous fields, including machine learning, example acknowledgment, picture investigation, data recovery, and bioinformatics.
Group examination itself is not one particular calculation, but rather the general errand to be comprehended. It can be accomplished by different calculations that contrast altogether in their thought of what constitutes a bunch and how to productively discover them. Well known ideas of bunches incorporate gatherings with little separations among the group individuals, thick ranges of the information space, interims or specific factual disseminations. Bunching can in this manner be defined as a multi-target streamlining issue. The suitable bunching calculation and parameter settings (counting values, for example, the separation capacity to utilize, a thickness limit or the quantity of expected groups) rely upon the individual information set and planned utilization of the outcomes. Bunch investigation accordingly is not a programmed undertaking, but rather an iterative procedure of information disclosure or intelligent multi-target streamlining that includes trial and disappointment. It will regularly be important to change information pre-processing and model parameters until the outcome accomplishes the sought properties.
Other than the term bunching, there are various terms with comparative implications, including programmed arrangement, numerical scientific categorization, botryology and typological investigation. The unpretentious contrasts are frequently in the utilization of the outcomes: while in information mining, the subsequent gatherings are the matter of enthusiasm, in programmed order the subsequent discriminative force is of hobby. This frequently prompts misconceptions between specialists originating from the fields of information mining and machine learning, since they utilize the same terms and regularly the same calculations, however have distinctive objectives.
To open the matlab code pdf, click here